前言
高可用Kubernetes集群通常使用多个节点运行控制平面组件,并且这些组件通常会有备份或者多个副本以防止单点故障。节点层面的工作负载则会被调度到多个健康节点上。
背景需求
K8s常见的稳定性痛点
- 痛点1:在发布、弹性等高峰期,集群控制面服务时断时续,甚至完全不可用
面对大流量请求,如果控制面没有自动弹性扩容能力,会无法对负载自适应、导致控制面服务不可用。
例如:客户端存在高频度持续 LIST 集群中的大量资源,集群 apiserver/etcd 无法自动弹性就可能联动出现OOM。
ACK Pro托管版K8s可以对控制面组件根据负载压力做HPA和VPA,可以有效解决该痛点。
- 痛点2:集群节点批量NotReady导致雪崩,严重影响业务!
部分节点出现NotReady,节点上Pod被驱逐调度到健康节点,健康节点由于压力过大也变为NotReady,加剧产生了更多NotReady的节点,业务持续重启。
ACK提供了托管节点池功能,可以对出现NotReady的异常节点治愈,重新拉会 Ready 状态,可以有效解决该痛点。
- 痛点3:业务高峰期需快速弹性,节点上拉取Pod镜像耗时长达分钟级,影响业务
节点上kubelet并发拉取镜像遇到网络带宽限制,需要镜像加速功能支持。
ACR提供了基于DADI(Data Accelerator for Disaggregated Infrastructure)的按需镜像加载和P2P镜像加速的功能,可以加速镜像拉取,可以有效解决该痛点。
- 痛点4:Master节点/组件运维复杂度高,包含资源配置、参数调优、升级管理等
需要大量的线上场景分析和优化、故障处理、规模压测等,来分析、整理并落地最佳实践和配置。
ACK Pro托管版K8s在全网的规模体量上万集群,具有自动弹性和生命周期管理的运维管理架构,有丰富的优化、应急处理等经验,持续将最佳实践和参数优化对托管组件升级。
K8s稳定性体现
- 服务可用性
- 处理时延
- 请求QPS与流量吞吐
- 资源水位
高可用集群建设
Kubernetes集群架构
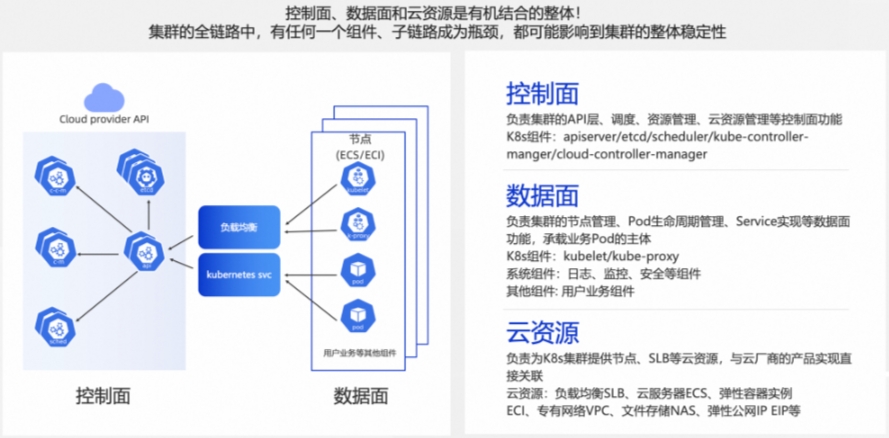
高可用架构设计
单Master集群
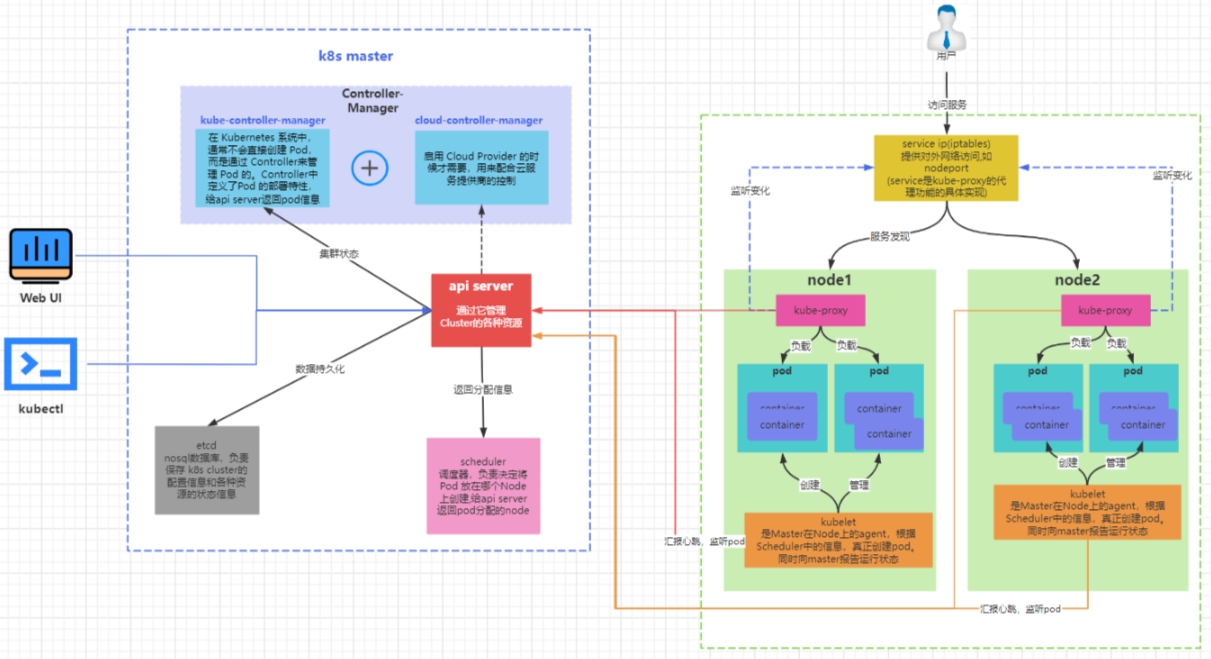
k8s集群是由一组运行k8s的节点组成的,节点可以是物理机、虚拟机或者云服务器。k8s 集群中的节点分为两种角色:master 和 node。
master节点:master 节点负责控制和管理整个集群,它运行着一些关键的组件,如 kube-apiserver、kube-scheduler、kube-controller-manager 等。master 节点可以有一个或多个,如果有多个 master 节点,那么它们之间需要通过 etcd 这个分布式键值存储来保持数据的一致性。
node节点:node 节点是承载用户应用的工作节点,它运行着一些必要的组件,如 kubelet、kube-proxy、container runtime 等。node 节点可以有一个或多个,如果有多个 node 节点,那么它们之间需要通过网络插件来实现通信和路由。
一般情况下我们会搭建单master多node集群。它是一种常见的 k8s 集群架构,它只有一个 master 节点和多个 node 节点。
这种架构的优点是简单易搭建,适合用于学习和测试 k8s 的功能和特性。这种架构的缺点是master节点成为了单点故障,如果 master 节点出现问题,那么整个集群就无法正常工作。
多master节点集群
- 分类
- 应用负载均衡集群
- 存储高可用集群
应用负载均衡集群
- 集群架构
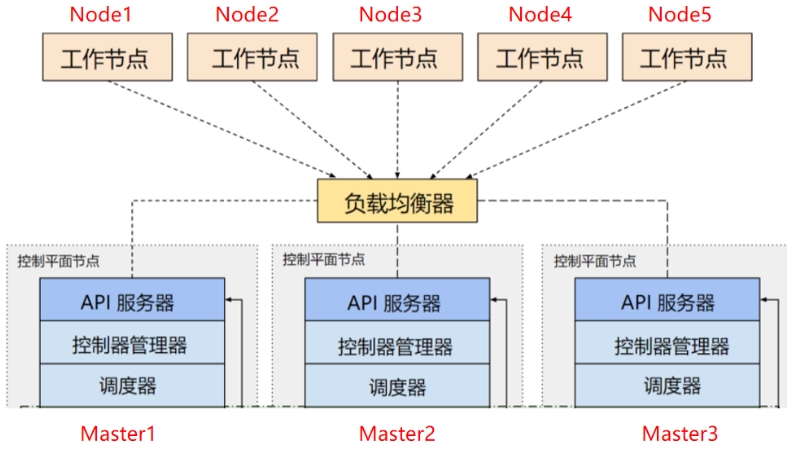
kubernetes多master集群是指使用多个master节点来提高集群的可用性和容错性的方案。
master节点是负责控制和管理集群中的资源和服务的节点,它运行着以下组件:
1.kube-apiserver:提供了HTTP REST接口的关键服务进程,是集群中所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。
2.kube-scheduler:负责资源调度(Pod调度)的进程,相当于公交公司的“调度室”。
3.kube-controller-manager:集群中所有资源对象的自动化控制中心,可以将其理解为资源对象的“大总管”。实现kubernetes master集群有多种方式,根据不同的需求和场景,可以选择合适的方式来搭建和运维master集群。
一般来说,根据实现方式,负载均衡集群可以分为以下几种方案:
1.硬件负载均衡:硬件负载均衡是使用专门的硬件设备来实现负载均衡的方案,如 F5、Cisco 等。硬件负载均衡的优点是性能高、稳定性强,缺点是成本高、扩展性差。
2.软件负载均衡:软件负载均衡是使用普通的服务器和软件来实现负载均衡的方案,如 Nginx、HAProxy 等。软件负载均衡的优点是成本低、扩展性好,缺点是性能低、稳定性差。
3.混合负载均衡:混合负载均衡是结合硬件和软件来实现负载均衡的方案,如使用硬件设备作为全局入口,使用软件作为局部分发。混合负载均衡的优点是兼顾了性能和成本,缺点是复杂度高、维护难。
存储高可用集群
etcd:分布式键值存储系统,用于保存集群中所有资源对象的状态和元数据。
k8s配置高可用(HA)Kubernetes etcd集群。
你可以设置 以下两种HA 集群:
1.使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存
2.使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行
- 集群架构
- 堆叠(Stacked)etcd拓扑–内置etcd集群
堆叠(Stacked)HA集群是一种这样的拓扑,其中 etcd 分布式数据存储集群堆叠在 kubeadm 管理的控制平面节点上,作为控制平面的一个组件运行。
每个控制平面节点运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例。 kube-apiserver 使用负载均衡器暴露给工作节点。
每个控制平面节点创建一个本地etcd成员(member),这个 etcd 成员只与该节点的 kube-apiserver 通信。 这同样适用于本地 kube-controller-manager 和 kube-scheduler 实例。
这种拓扑将控制平面和 etcd 成员耦合在同一节点上。相对使用外部 etcd 集群, 设置起来更简单,而且更易于副本管理。
然而,堆叠集群存在耦合失败的风险。如果一个节点发生故障,则etcd 成员和控制平面实例都将丢失, 并且冗余会受到影响。你可以通过添加更多控制平面节点来降低此风险。
因此,你应该为 HA 集群运行至少三个堆叠的控制平面节点。
这是 kubeadm 中的默认拓扑。当使用 kubeadm init 和 kubeadm join --control-plane 时, 在控制平面节点上会自动创建本地 etcd 成员。
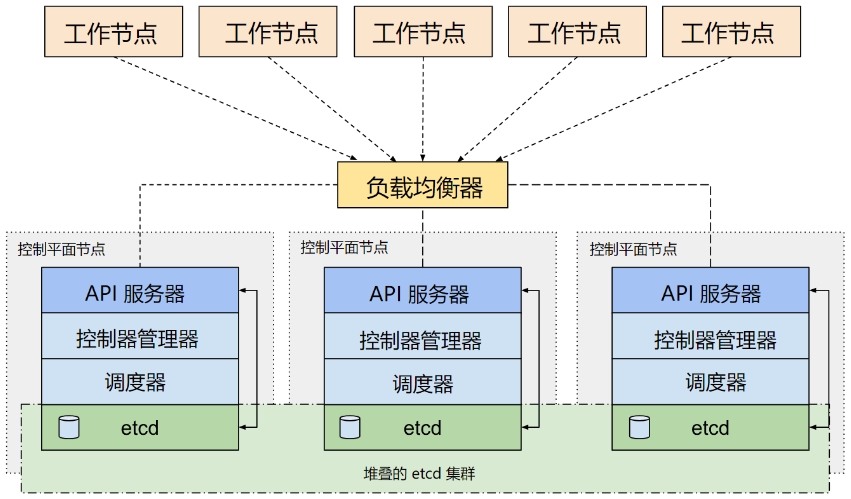
- 外部etcd拓扑–外部etcd集群
具有外部 etcd 的 HA 集群是一种这样的拓扑, 其中 etcd 分布式数据存储集群在独立于控制平面节点的其他节点上运行。
就像堆叠的 etcd 拓扑一样,外部 etcd 拓扑中的每个控制平面节点都会运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例。
同样,kube-apiserver 使用负载均衡器暴露给工作节点。但是 etcd 成员在不同的主机上运行, 每个 etcd 主机与每个控制平面节点的 kube-apiserver 通信。
这种拓扑结构解耦了控制平面和 etcd 成员。因此它提供了一种 HA 设置, 其中失去控制平面实例或者 etcd 成员的影响较小,并且不会像堆叠的 HA 拓扑那样影响集群冗余。
但此拓扑需要两倍于堆叠 HA 拓扑的主机数量。 具有此拓扑的 HA 集群至少需要三个用于控制平面节点的主机和三个用于 etcd 节点的主机。
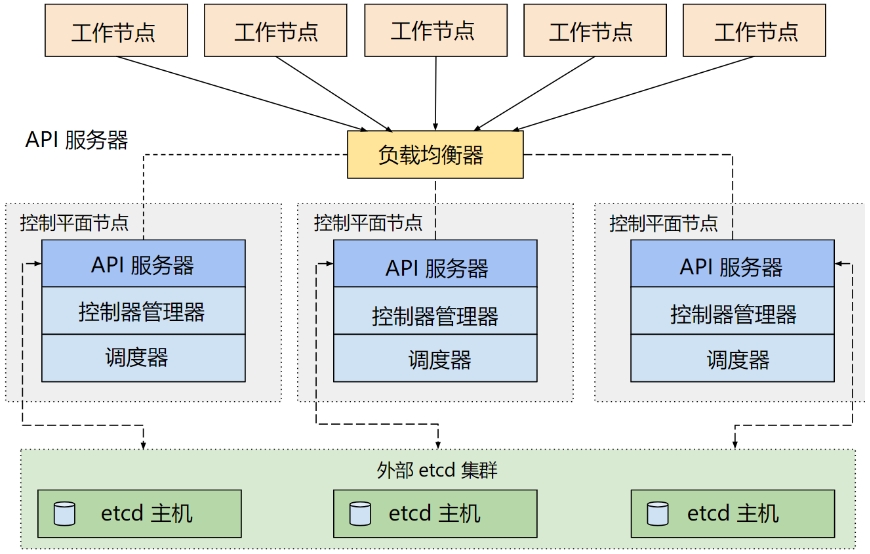
- 堆叠(Stacked)etcd拓扑–内置etcd集群
Kubernetes HA部署
HA集群架构设计
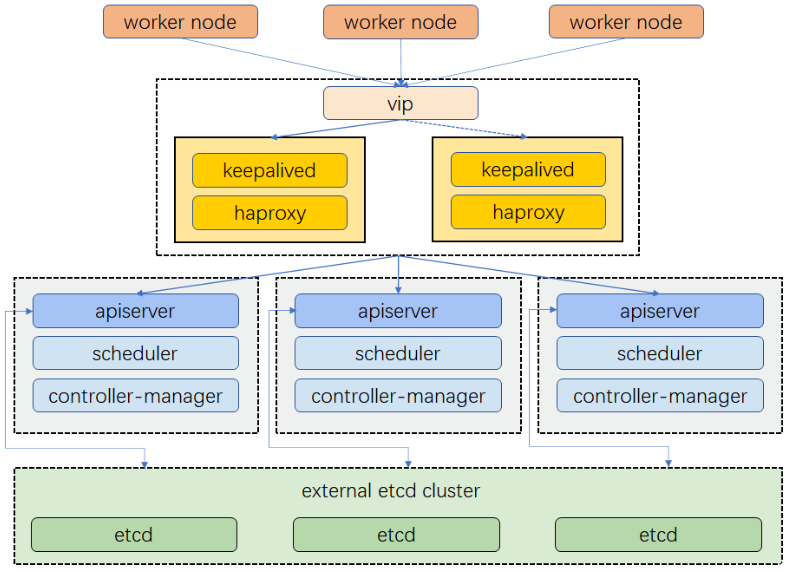
准备工作
CI/CD DevOps
Zadig安装
项目集成
服务集成示例
附录
k8s pod常用运维命令
如何创建自己的Helm Chart?
名称解释
| 名称 | 解释说明 | 备注 |
|---|---|---|
| kubectl | ||
| keepalived | ||
| haproxy | ||
| pod | pod是k8s的最小工作单元。每个pod包含一个或者多个容器。pod中的容器会作为一个整体被master调度到一个node上运行 | |
| controller | k8s通常不会直接创建pod,而是通过controller来管理pod的。controller中定义了pod的部署特性,比如有几个副本,在什么样的node上运行等。 | |
| name |
参考资料
- 使用kubeadm创建一个高可用etcd集群
- lvs+keepalived部署kubernetes(k8s)高可用集群
- Kubernetes核心架构与高可用集群详解
- flink-helm-chart
- Artifact Hub
- Helm-chart学习-简单介绍与使用
- Harbor安装
文档信息
- 本文作者:Tony
- 本文链接:https://lj-michale.top/2024/04/12/kubernetes_ha_cluster/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)